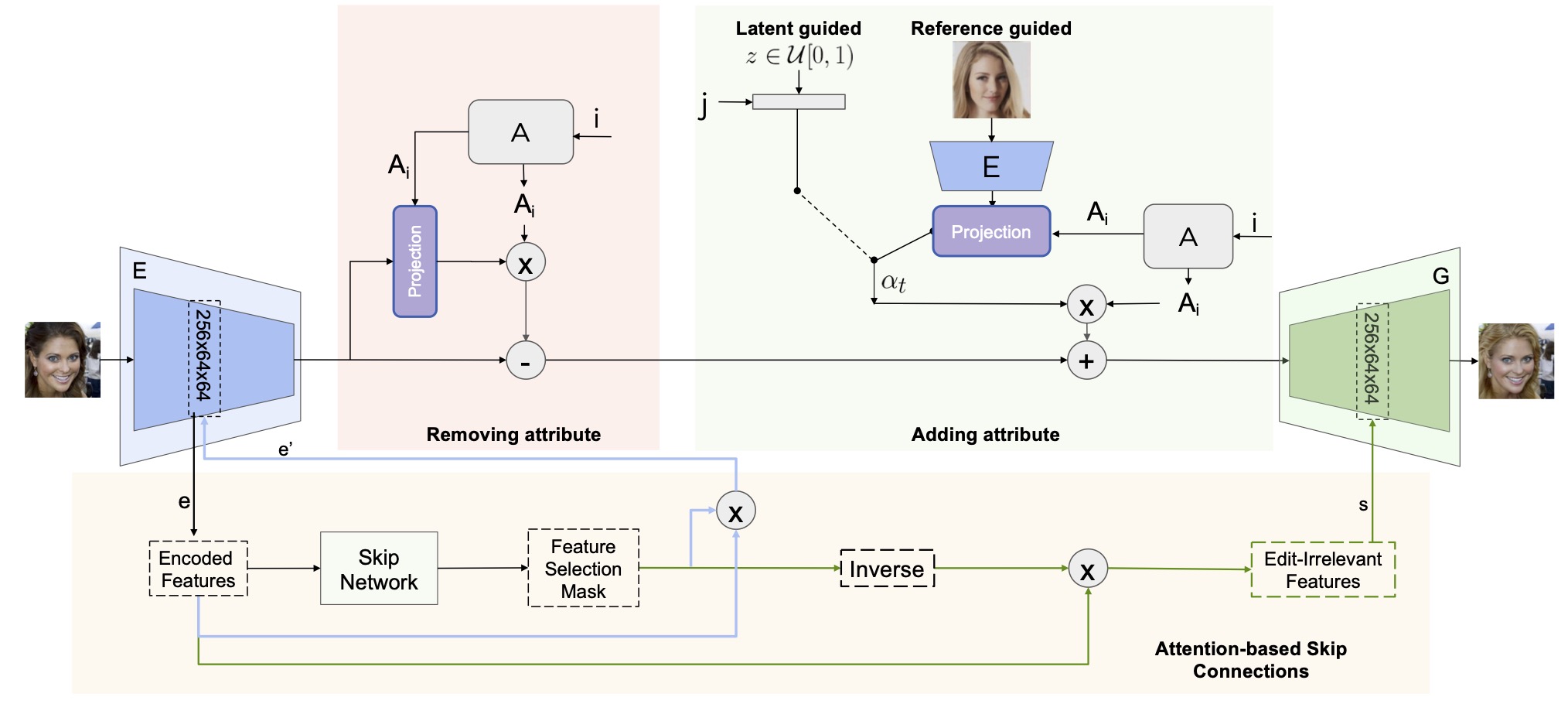
Interpolation Results
VecGAN++ can interpolate through attribute edits through changing the translation strength for the desired semantic. Our model can edit smile, bangs, eyeglasses, hair color, age and gender tags where interpolation results are given below.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Input |
Smile |
Bangs |
Eyeglasses |
Hair |
Age |
Gender |
Generalization Results
VecGAN++ also generalizes well to out-of-domain images. Smile interpolation results are provided, using samples from MetFaces dataset.
 |
 |
 |
 |
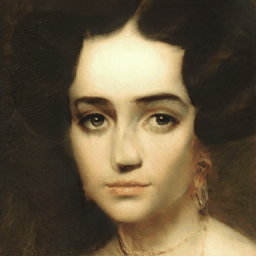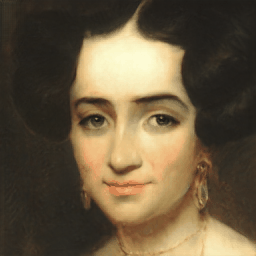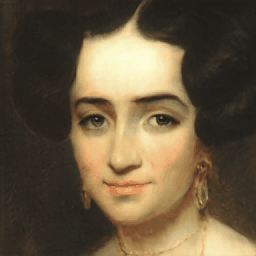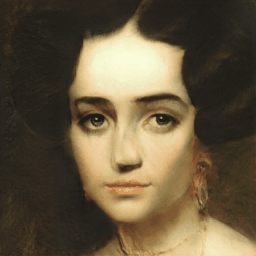 |
 |